Featured Posts



Come ChatLab Sfrutta la Tecnologia RAG?
April 18th, 2025 by Bartek Mularz

Come ChatLab Sfrutta la Tecnologia RAG?
In ChatLab, creiamo chatbot intelligenti che rivoluzionano le interazioni online. Il motore principale delle loro capacità è una tecnologia innovativa chiamata Retrieval-Augmented Generation (RAG). Questa forma la base del nostro sistema, permettendoci di offrire soluzioni che vanno oltre le conversazioni standard.
Nel mondo dei chatbot, ci sono due principali metodi di addestramento. Comprendere i diversi tipi di chatbot ti aiuta a vedere come questi approcci di addestramento differiscono. Il primo prevede un addestramento intensivo di reti neurali complesse—un processo intricato, dispendioso in termini di tempo e costoso. Il secondo approccio, che impieghiamo con successo in ChatLab, è il RAG. Non solo è più semplice, più economico e veloce da implementare, ma consente anche ai nostri chatbot di accedere a fonti esterne di informazioni illimitate—come i tuoi file. Questo ci permette di generare risposte altamente precise, contestualizzate e personalizzate.
Ti invitiamo a continuare a leggere per approfondire come la tecnologia RAG alimenta ChatLab!
Cos'è esattamente il RAG?
Per capire come funziona il nostro sistema, vale la pena esaminare più da vicino la Retrieval-Augmented Generation. Sebbene interagire con un chatbot possa sembrare intuitivo dal punto di vista dell'utente, comprendere i meccanismi dietro il suo funzionamento ti permette di apprezzarne appieno il potenziale.
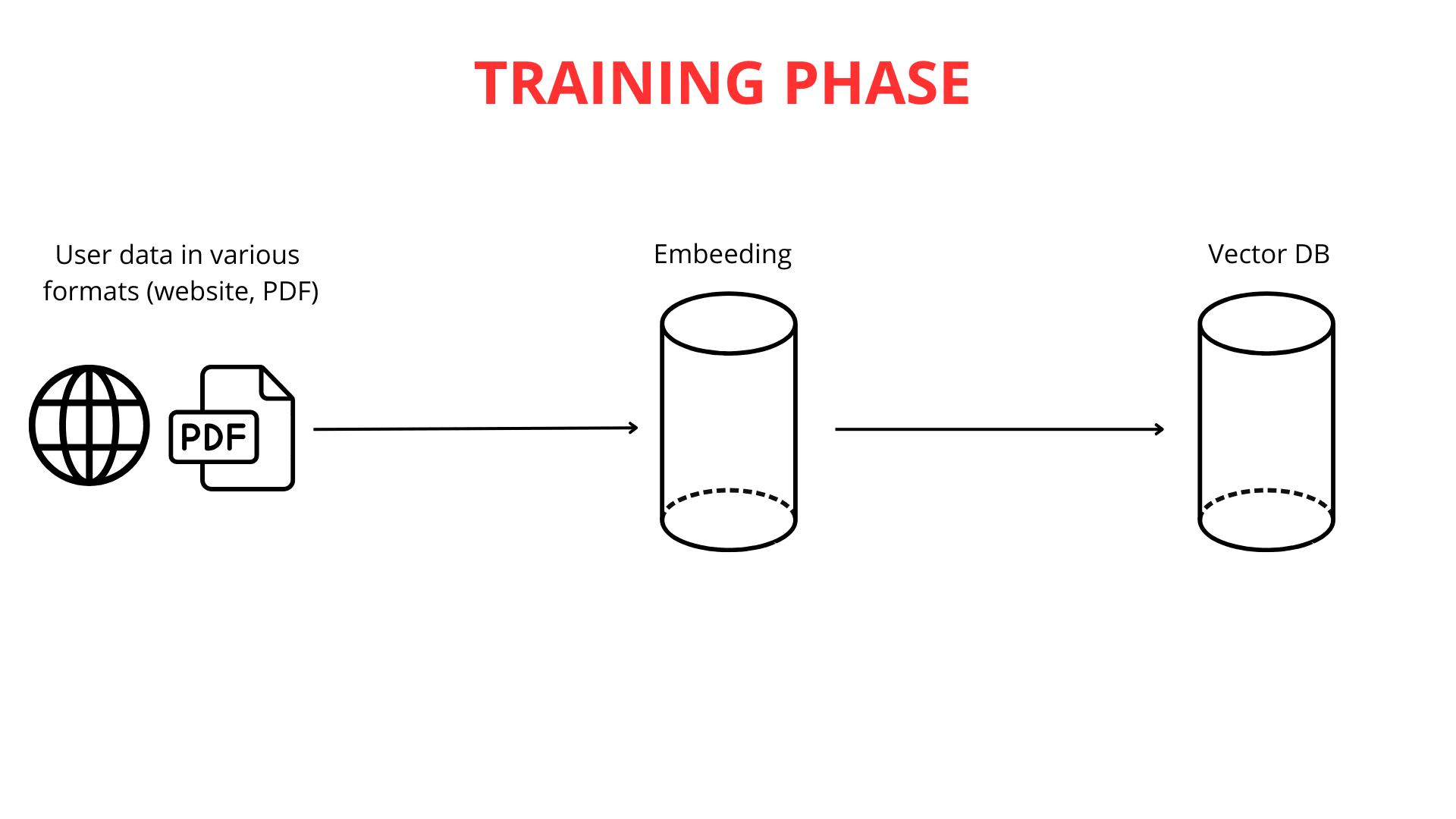
Costruire un chatbot intelligente è un processo radicato nella conoscenza di più discipline scientifiche. Il primo e più cruciale passo è alimentare il chatbot con dati. In ChatLab, lo abilitiamo in diversi modi convenienti: caricando contenuti del sito web, documentazione estesa o anche i tuoi file PDF. Le possibilità di personalizzare la base di conoscenza secondo le tue esigenze sono praticamente illimitate.
La fase successiva prevede la suddivisione di testi lunghi in frammenti più piccoli (fino a 600 token ciascuno), rendendo più facile per il sistema elaborare le informazioni in modo efficiente. Una volta caricati e segmentati i dati, inizia il processo di mappatura vettoriale.
È importante sottolineare che la mappatura testo-vettore è fondamentale per la funzionalità del RAG. Potenti motori di modelli di linguaggio di grandi dimensioni (LLM) sono responsabili della generazione di queste rappresentazioni vettoriali.
Il Ruolo della Mappatura Vettoriale nella Comprensione del Testo
La vettorizzazione del testo consiste essenzialmente nel convertire le parole in elenchi di numeri—costruiti in modo tale che le parole con significati simili ricevano rappresentazioni numeriche simili (vettori). Questo permette al nostro chatbot di "comprendere" le relazioni tra diverse sequenze di parole. Ad esempio, le parole "grande" e "enorme" verrebbero trasformate in elenchi numerici molto simili, mentre "grande" e "formica" riceverebbero rappresentazioni completamente diverse.
Analizzando queste somiglianze e differenze numeriche, il chatbot può dedurre che "gatto" e "cane" sono più strettamente correlati di "gatto" e "verde".
Una volta generati i vettori, queste rappresentazioni numeriche della conoscenza vengono memorizzate in un database vettoriale insieme al contenuto originale. Il database vettoriale funge da catalogo avanzato di conoscenze vettorializzate, ottimizzato per un rapido recupero di significati correlati.
Il Database Vettoriale: Una Biblioteca di Conoscenza Intelligente
Per comprendere meglio come funziona un database vettoriale, usiamo l'analogia di una biblioteca con un sistema di ricerca intelligente. Ogni "libro" (frammento di testo) è "etichettato" da un vettore unico (una sequenza di numeri). Questo codice contiene numeri multipli che rappresentano l'autore, lo stile e l'argomento del libro. Due libri su argomenti simili avranno codici molto simili.
In questa "biblioteca", i libri sono collocati su "scaffali" in uno spazio multidimensionale basato sui loro codici. I libri con codici simili sono raggruppati vicini—proprio come i libri nella stessa categoria ma ulteriormente organizzati da sottili somiglianze di contenuto. Quando fai una domanda (ad esempio, "Qual è la ricetta della torta al cioccolato?"), viene convertita in un tale "codice". Il sistema di ricerca intelligente nel database vettoriale scansiona gli "scaffali" (frammenti di testo) per i codici che corrispondono più strettamente al codice della tua query.
L'algoritmo identifica rapidamente i "libri" (frammenti) più probabilmente contenenti la risposta. Invece di cercare nell'intera "biblioteca", il chatbot individua istantaneamente i pezzi di conoscenza più rilevanti in termini di significato. Questo assicura risposte più rapide, accurate e focalizzate sul contesto.
Cosa Succede Quando Fai una Domanda?
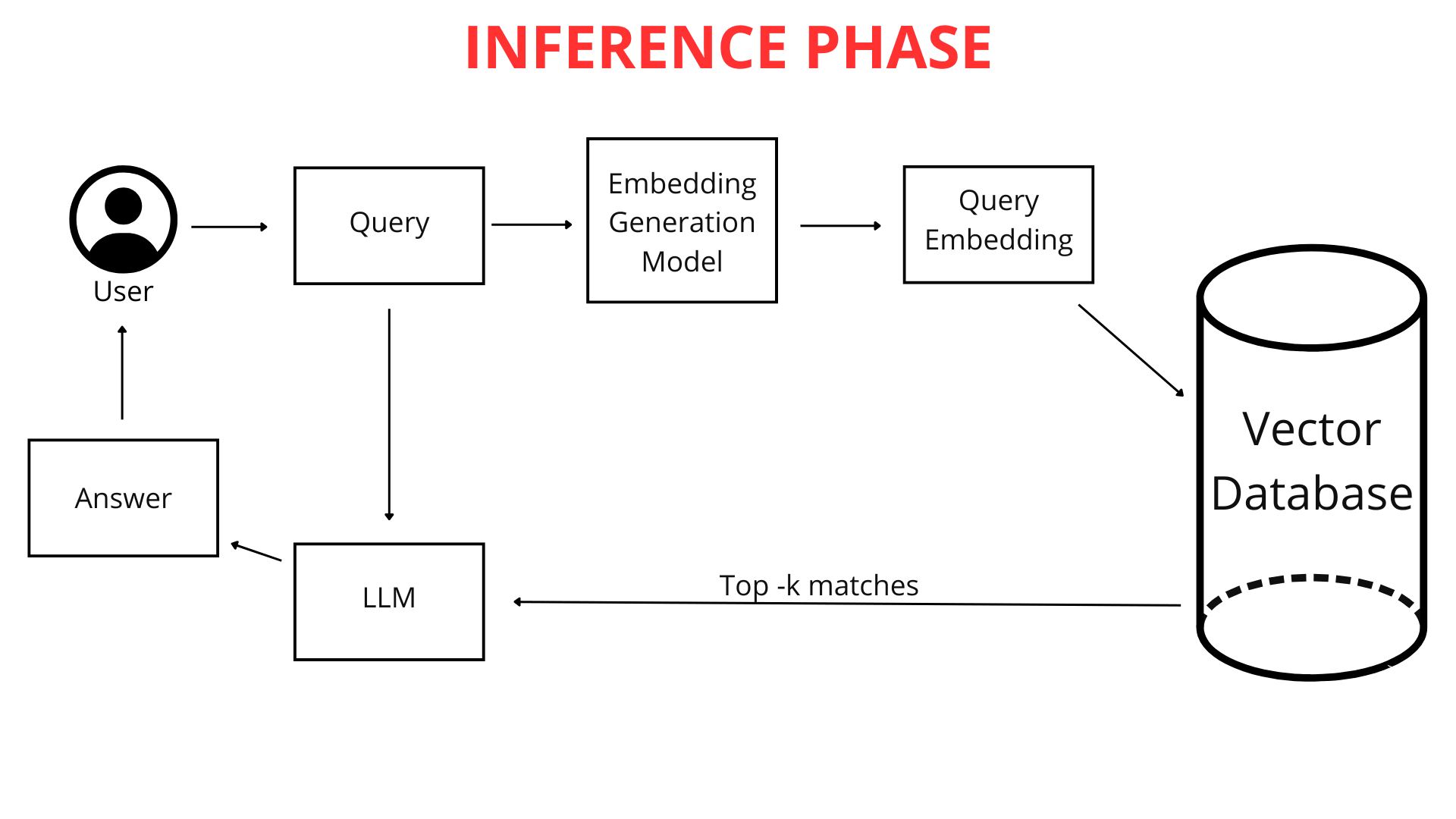
Quando, come utente, digiti una domanda nel chatbot (ad esempio, "Che tempo farà a Cracovia domani?"), non viene immediatamente confrontata con la conoscenza del chatbot in forma di testo grezzo. Prima, la domanda viene mappata in un vettore numerico. Poiché sia la tua domanda che l'intera base di conoscenza del chatbot sono rappresentate nello stesso formato—come mappe vettoriali (elenchi di numeri)—il chatbot può confrontarle in modo efficiente. Identifica i frammenti della sua conoscenza più strettamente correlati al vettore della tua query, permettendogli di generare la migliore risposta possibile.
RAG Entra in Azione
Qui è dove la tecnologia RAG gioca un ruolo cruciale. Il sistema RAG analizza la rappresentazione vettoriale della tua query e la utilizza per cercare nel database vettoriale gli elenchi numerici più simili (più vicini nello spazio multidimensionale). Questi vettori più simili puntano ai frammenti di file originali più pertinenti alla tua domanda.
RAG agisce come un "ponte" intelligente tra la tua query e la vasta base di conoscenza del chatbot. Consente il recupero dinamico solo delle informazioni più necessarie per l'LLM (Large Language Model) per formulare una risposta. Un LLM, in termini semplici, è un algoritmo avanzato e un dataset addestrato su enormi quantità di testo, capace di comprendere e generare linguaggio naturale. Per saperne di più su questa tecnologia, scopri come funziona effettivamente ChatGPT. Gli LLM possono rispondere a domande e persino creare contenuti diversi.
Senza RAG, un LLM dovrebbe fare affidamento esclusivamente sulla sua conoscenza integrata, che potrebbe non includere dettagli specifici dai tuoi file o potrebbe essere obsoleta. Grazie a RAG, il chatbot acquisisce la capacità di attingere a conoscenze esterne aggiuntive proprio quando fai una domanda. Questa conoscenza fresca proviene direttamente dai tuoi file caricati e dalle pagine web, che sono state adeguatamente elaborate.
La Differenza tra un Chatbot Con e Senza RAG
La differenza chiave sta in come viene acceduta la conoscenza.
Conoscenza Addestrata (Senza RAG): Questa è la conoscenza "integrata" dell'LLM, acquisita durante l'addestramento intensivo su vasti dataset prima della tua interazione con ChatLab. Se chiedi qualcosa non coperto da quei dati, il modello potrebbe semplicemente non conoscere la risposta.
Conoscenza dei Tuoi File (Usata tramite RAG): Questa è la tua conoscenza unica e specializzata che fornisci al chatbot. RAG consente al chatbot di accedere dinamicamente a questa conoscenza quando risponde alle domande, combinandola con la sua conoscenza di addestramento generale per generare una risposta completa. Questo approccio alimenta la moderna IA conversazionale per il servizio clienti.
Un'Analogia:
Immagina un LLM come uno studente estremamente intelligente che ha letto innumerevoli libri (dati di addestramento) e possiede una conoscenza generale impressionante. Ora, gli fornisci i tuoi appunti di lezione e dispense (i tuoi file). RAG agisce come un sistema che permette a questo studente di controllare rapidamente i tuoi appunti quando risponde a una domanda, piuttosto che fare affidamento solo su ciò che ricorda da tutti quei libri. Questo miglioramento garantisce risposte migliori, più precise e—soprattutto—più aggiornate.
Grazie a RAG, il chatbot può espandere la sua conoscenza con i tuoi dati unici e usarli attivamente nelle interazioni. Non è limitato solo a ciò che ha imparato durante il suo addestramento iniziale.
Ecco perché RAG è inestimabile quando hai bisogno che un chatbot risponda a domande sulle tue informazioni specifiche—dettagli che non sono pubblicamente disponibili o sono troppo di nicchia per essere inclusi nei dati di addestramento generali dell'LLM.
Se la tua domanda è: "Dove posso trovare libri sullo spazio?", prima che il "bibliotecario" (chatbot) inizi a "cercare sugli scaffali", prima "traduce" la tua domanda nel "linguaggio degli scaffali"—identificando la categoria appropriata del libro. Creare una mappa vettoriale della tua domanda è come catalogare la tua query in categorie che il chatbot comprende e può accedere tramite il database vettoriale.
La Fase di Addestramento e Utilizzo della Conoscenza
Come spiegato in precedenza, la tua domanda viene convertita in un elenco di numeri che rappresentano il suo significato. Il chatbot quindi cerca nel database vettoriale i vettori più simili che rappresentano frammenti di conoscenza. Più le rappresentazioni vettoriali sono vicine, maggiore è la somiglianza tra la tua domanda e quei frammenti di conoscenza.
Il chatbot seleziona i frammenti di conoscenza pre-elaborati che corrispondono più strettamente—quelli i cui vettori sono più vicini alla mappa vettoriale della tua domanda. Importante, quando analizza la tua query, ChatLab considera non solo la domanda stessa ma anche il contesto dell'intera conversazione fino a quel momento. Questo permette al sistema RAG di selezionare più precisamente le migliori informazioni dalle fonti di conoscenza connesse.
Ad esempio, se prima chiedi dei "modelli di telefoni più recenti" e poi segui con "Hanno buone fotocamere?", il chatbot—ricordando il contesto della conversazione—capisce che ti stai ancora riferendo a quei telefoni specifici.
I frammenti di conoscenza selezionati vengono combinati con la tua domanda originale e le istruzioni dalla sezione "Ruolo & Comportamento". Queste istruzioni, note anche come prompt, sono il nostro set personalizzato di linee guida per il chatbot. Se vogliamo che il chatbot aggiunga sempre un link alla fonte alla fine della sua risposta o saluti gli utenti in un modo specifico, lo includiamo nel prompt.
Questo crea una query aumentata, che viene poi passata al "cervello" del chatbot—il modello di linguaggio di grandi dimensioni (LLM) di OpenAI, Google o altri fornitori.
Il modello di linguaggio analizza questo complesso insieme di informazioni: il prompt, la cronologia della conversazione e la conoscenza recuperata per la query dell'utente. Inoltre, l'LLM sfrutta la sua conoscenza generale del mondo per generare una risposta. Questo consente esperienze cliente altamente personalizzate con l'AI. Infine, la risposta raffinata e perfezionata viene presentata nell'interfaccia pulita di ChatLab.
Riepilogo
In questo articolo, abbiamo esaminato l'architettura del sistema RAG nella funzionalità dei chatbot—dall'input dei dati alla generazione delle risposte. RAG è un componente fondamentale dei moderni sistemi di conversazione, consentendo un uso efficiente della conoscenza esterna. Aziende come ChatLab integrano attivamente questa tecnologia rivoluzionaria nei loro prodotti, offrendo capacità di interazione avanzate e intelligenti ai clienti.
Sebbene il sistema RAG abbia una certa complessità tecnica, il suo impatto sul testo generato dall'IA è innegabile. Il fatto che sia utilizzato con successo da aziende tecnologiche leader come Google, Microsoft e Amazon sottolinea il suo ruolo fondamentale nell'evoluzione dinamica dell'intelligenza artificiale.
Pronto a sperimentare la tecnologia RAG in prima persona? Esplora le funzionalità di ChatLab o scopri come creare il tuo chatbot AI alimentato da questa tecnologia.