Featured Posts



Wie ChatLab die RAG-Technologie nutzt
April 18th, 2025 by Bartek Mularz

Wie ChatLab die RAG-Technologie nutzt
Bei ChatLab entwickeln wir intelligente Chatbots, die Online-Interaktionen revolutionieren. Der Schlüssel zu ihren Fähigkeiten ist eine innovative Technologie namens Retrieval-Augmented Generation (RAG). Diese bildet das Fundament unseres Systems und ermöglicht es uns, Lösungen zu liefern, die über standardisierte Gespräche hinausgehen.
In der Welt der Chatbots gibt es zwei Haupttrainingsmethoden. Das Verständnis der verschiedenen Arten von Chatbots hilft Ihnen zu sehen, wie sich diese Trainingsansätze unterscheiden. Die erste umfasst das intensive Training komplexer neuronaler Netzwerke – ein Prozess, der kompliziert, zeitaufwendig und kostspielig ist. Der zweite Ansatz, den wir bei ChatLab erfolgreich anwenden, ist RAG. Er ist nicht nur einfacher, kostengünstiger und schneller zu implementieren, sondern ermöglicht es unseren Chatbots auch, auf unbegrenzte externe Informationsquellen zuzugreifen – wie z.B. Ihre eigenen Dateien. Dies erlaubt uns, Antworten zu generieren, die hochpräzise, kontextbewusst und personalisiert sind.
Wir laden Sie ein, weiterzulesen und tiefer einzutauchen, wie die RAG-Technologie ChatLab antreibt!
Was genau ist RAG?
Um zu verstehen, wie unser System funktioniert, lohnt es sich, einen genaueren Blick auf die Retrieval-Augmented Generation zu werfen. Während die Interaktion mit einem Chatbot aus der Sicht eines Nutzers intuitiv erscheinen mag, ermöglicht das Verständnis der Mechanismen hinter seinem Betrieb, sein Potenzial voll zu schätzen.
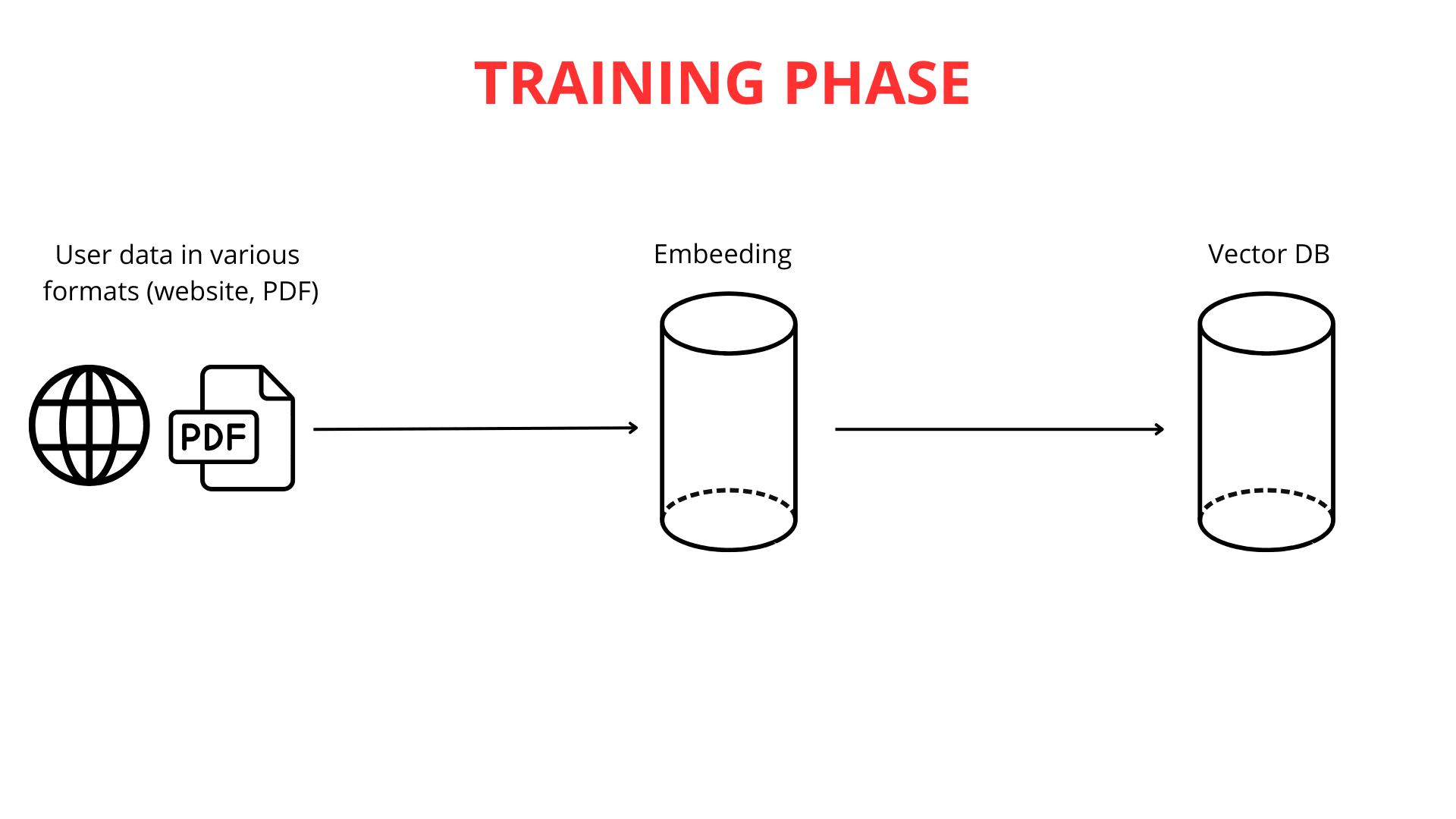
Der Aufbau eines intelligenten Chatbots ist ein Prozess, der auf Wissen aus mehreren wissenschaftlichen Disziplinen basiert. Der erste und wichtigste Schritt ist das Füttern des Chatbots mit Daten. Bei ChatLab ermöglichen wir dies auf mehrere bequeme Arten: durch Hochladen von Website-Inhalten, umfangreicher Dokumentation oder sogar Ihrer eigenen PDF-Dateien. Die Möglichkeiten, die Wissensbasis an Ihre Bedürfnisse anzupassen, sind nahezu grenzenlos.
Der nächste Schritt besteht darin, lange Texte in kleinere Abschnitte (jeweils bis zu 600 Tokens) zu zerlegen, um es dem System zu erleichtern, Informationen effizient zu verarbeiten. Sobald die Daten hochgeladen und segmentiert sind, beginnt der Vektorkartierungsprozess.
Es ist wichtig zu betonen, dass die Text-zu-Vektor-Kartierung entscheidend für die Funktionalität von RAG ist. Leistungsstarke Large Language Model (LLM) Engines sind verantwortlich für die Generierung dieser Vektorrepräsentationen.
Die Rolle der Vektorkartierung im Textverständnis
Die Textvektorisierung ist im Wesentlichen die Umwandlung von Wörtern in Zahlenlisten – so konstruiert, dass Wörter mit ähnlichen Bedeutungen ähnliche numerische Repräsentationen (Vektoren) erhalten. Dies ermöglicht es unserem Chatbot, "Beziehungen" zwischen verschiedenen Wortsequenzen zu "verstehen". Zum Beispiel würden die Wörter "groß" und "riesig" in sehr ähnliche Zahlenlisten umgewandelt, während "groß" und "Ameise" völlig unterschiedliche Repräsentationen erhalten würden.
Durch die Analyse dieser numerischen Ähnlichkeiten und Unterschiede kann der Chatbot ableiten, dass "Katze" und "Hund" enger miteinander verwandt sind als "Katze" und "grün".
Sobald Vektoren generiert sind, werden diese numerischen Repräsentationen des Wissens zusammen mit dem Originalinhalt in einer Vektordatenbank gespeichert. Die Vektordatenbank fungiert als fortschrittlicher Katalog des vektorisierten Wissens, optimiert für die schnelle Abrufung verwandter Bedeutungen.
Die Vektordatenbank: Eine intelligente Wissensbibliothek
Um besser zu verstehen, wie eine Vektordatenbank funktioniert, verwenden wir die Analogie einer Bibliothek mit einem intelligenten Suchsystem. Jedes "Buch" (Textfragment) ist durch einen einzigartigen Vektor (eine Zahlenfolge) "markiert". Dieser Code enthält mehrere Zahlen, die den Autor, den Stil und das Thema des Buches darstellen. Zwei Bücher zu ähnlichen Themen werden sehr ähnliche Codes haben.
In dieser "Bibliothek" werden Bücher basierend auf ihren Codes in einem mehrdimensionalen Raum auf "Regalen" platziert. Bücher mit ähnlichen Codes werden nahe beieinander gruppiert – ähnlich wie Bücher in derselben Kategorie, aber weiter organisiert nach subtilen Inhaltsähnlichkeiten. Wenn Sie eine Frage stellen (z.B. "Was ist das Rezept für Schokoladenkuchen?"), wird sie in einen solchen "Code" umgewandelt. Das intelligente Suchsystem in der Vektordatenbank durchsucht die "Regale" (Textfragmente) nach Codes, die am ehesten mit dem Code Ihrer Anfrage übereinstimmen.
Der Algorithmus identifiziert schnell die "Bücher" (Fragmente), die am wahrscheinlichsten die Antwort enthalten. Anstatt die gesamte "Bibliothek" zu durchsuchen, kann der Chatbot sofort die relevantesten Wissensstücke im Hinblick auf die Bedeutung identifizieren. Dies gewährleistet schnellere, genauere und kontextbezogene Antworten.
Was passiert, wenn Sie eine Frage stellen?
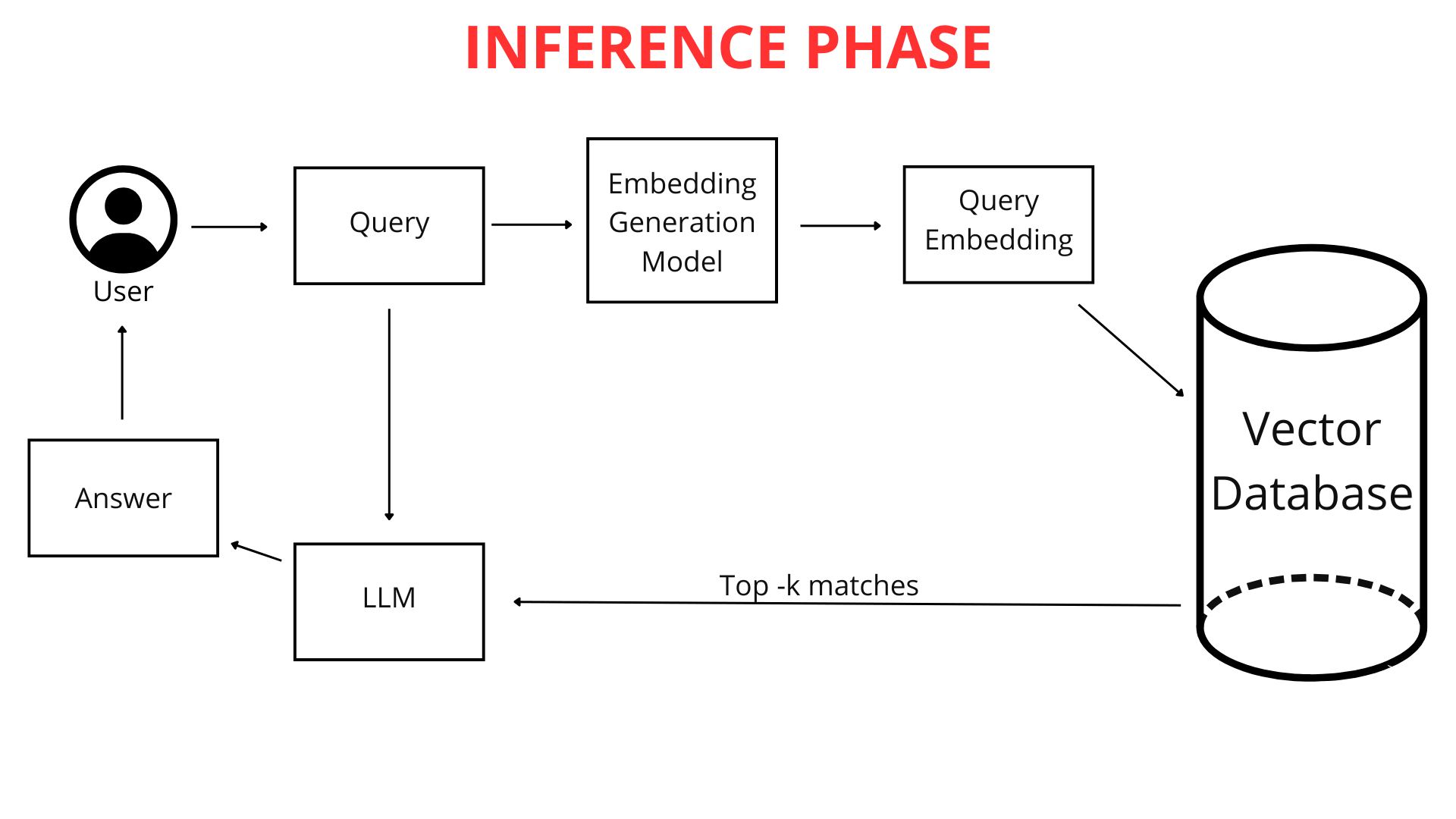
Wenn Sie als Nutzer eine Frage in den Chatbot eingeben (z.B. "Wie wird das Wetter morgen in Krakau?"), wird sie nicht sofort mit dem Wissen des Chatbots in Rohtextform verglichen. Zuerst wird die Frage in einen numerischen Vektor umgewandelt. Da sowohl Ihre Frage als auch die gesamte Wissensbasis des Chatbots im gleichen Format – als Vektorkarten (Zahlenlisten) – dargestellt sind, kann der Chatbot sie effizient vergleichen. Er identifiziert die Fragmente seines Wissens, die am engsten mit dem Vektor Ihrer Anfrage verwandt sind, und ermöglicht es ihm, die bestmögliche Antwort zu generieren.
RAG wird aktiv
Hier spielt die RAG-Technologie eine entscheidende Rolle. Das RAG-System analysiert die Vektorrepräsentation Ihrer Anfrage und nutzt sie, um in der Vektordatenbank nach den numerischen Listen zu suchen, die ihr am ähnlichsten sind (am nächsten im mehrdimensionalen Raum). Diese ähnlichsten Vektoren verweisen auf die ursprünglichen Dateifragmente, die am relevantesten für Ihre Frage sind.
RAG fungiert wie eine intelligente "Brücke" zwischen Ihrer Anfrage und der umfangreichen Wissensbasis des Chatbots. Es ermöglicht die dynamische Abrufung nur der Informationen, die das LLM (Large Language Model) benötigt, um eine Antwort zu formulieren. Ein LLM ist einfach ausgedrückt ein fortschrittlicher Algorithmus und Datensatz, der auf riesigen Textmengen trainiert wurde und in der Lage ist, natürliche Sprache zu verstehen und zu generieren. LLMs können Fragen beantworten und sogar vielfältige Inhalte erstellen.
RAG fungiert wie eine intelligente "Brücke" zwischen Ihrer Anfrage und der umfangreichen Wissensbasis des Chatbots. Um mehr über diese Technologie zu erfahren, sehen Sie sich an, wie ChatGPT tatsächlich funktioniert.
Ohne RAG müsste ein LLM sich ausschließlich auf sein eingebautes Wissen verlassen, das möglicherweise keine spezifischen Details aus Ihren Dateien enthält oder veraltet sein könnte. Dank RAG erhält der Chatbot die Fähigkeit, bei einer Frage auf zusätzliches externes Wissen zuzugreifen. Dieses frische Wissen stammt direkt aus Ihren hochgeladenen Dateien und Webseiten, die ordnungsgemäß verarbeitet wurden.
Der Unterschied zwischen einem Chatbot mit und ohne RAG
Der entscheidende Unterschied liegt darin, wie Wissen abgerufen wird.
Trainiertes Wissen (ohne RAG): Dies ist das "eingebaute" Wissen des LLM, das während des intensiven Trainings auf umfangreichen Datensätzen vor Ihrer Interaktion mit ChatLab erworben wurde. Wenn Sie nach etwas fragen, das in diesen Daten nicht enthalten ist, könnte das Modell die Antwort einfach nicht wissen.
Das Wissen Ihrer Dateien (verwendet über RAG): Dies ist Ihr einzigartiges, spezialisiertes Wissen, das Sie dem Chatbot zur Verfügung stellen. RAG ermöglicht es dem Chatbot, dieses Wissen dynamisch beim Beantworten von Fragen abzurufen und es mit seinem allgemeinen Trainingswissen zu kombinieren, um eine umfassende Antwort zu generieren. Dieser Ansatz treibt moderne konversationelle KI für den Kundenservice an.
Eine Analogie:
Stellen Sie sich ein LLM als einen extrem intelligenten Studenten vor, der unzählige Bücher (Trainingsdaten) gelesen hat und beeindruckendes Allgemeinwissen besitzt. Nun geben Sie ihm Ihre Vorlesungsnotizen und Handouts (Ihre Dateien). RAG fungiert als System, das es diesem Studenten ermöglicht, schnell Ihre Notizen zu überprüfen, wenn er eine Frage beantwortet, anstatt sich nur auf das zu verlassen, was er aus all diesen Büchern erinnert. Diese Erweiterung garantiert bessere, präzisere und – was am wichtigsten ist – aktuellere Antworten.
Dank RAG kann der Chatbot sein Wissen mit Ihren einzigartigen Daten erweitern und aktiv in Interaktionen nutzen. Er ist nicht nur auf das beschränkt, was er während seines anfänglichen Trainings gelernt hat.
Deshalb ist RAG von unschätzbarem Wert, wenn Sie einen Chatbot benötigen, der Fragen zu Ihren spezifischen Informationen beantwortet – Details, die nicht öffentlich verfügbar sind oder zu speziell sind, um in allgemeinen LLM-Trainingsdaten enthalten zu sein.
Wenn Ihre Frage lautet: "Wo finde ich Bücher über den Weltraum?", "übersetzt" der "Bibliothekar" (Chatbot) Ihre Frage zuerst in die "Sprache der Regale" – indem er die passende Buchkategorie identifiziert, bevor er mit der "Suche in den Regalen" beginnt. Die Erstellung einer Vektorkarte Ihrer Frage ist wie das Katalogisieren Ihrer Anfrage in Kategorien, die der Chatbot versteht und über die Vektordatenbank zugreifen kann.
Die Trainings- und Wissensnutzungsphase
Wie bereits erklärt, wird Ihre Frage in eine Liste von Zahlen umgewandelt, die ihre Bedeutung repräsentiert. Der Chatbot durchsucht dann die Vektordatenbank nach den ähnlichsten Vektoren, die Wissensfragmente darstellen. Je näher die Vektorrepräsentationen beieinander liegen, desto größer ist die Ähnlichkeit zwischen Ihrer Frage und diesen Wissensfragmenten.
Der Chatbot wählt die am besten passenden Fragmente seines vorverarbeiteten Wissens aus – diejenigen, deren Vektoren am nächsten zur Vektorkarte Ihrer Frage liegen. Wichtig ist, dass ChatLab bei der Analyse Ihrer Anfrage nicht nur die Frage selbst, sondern auch den Kontext des gesamten bisherigen Gesprächs berücksichtigt. Dies ermöglicht es dem RAG-System, präziser die besten Informationen aus verbundenen Wissensquellen auszuwählen.
Wenn Sie zum Beispiel zuerst nach "den neuesten Telefonmodellen" fragen und dann mit "Haben sie gute Kameras?" fortfahren, versteht der Chatbot – der sich an den Gesprächskontext erinnert –, dass Sie sich immer noch auf diese speziellen Telefone beziehen.
Die ausgewählten Wissensfragmente werden mit Ihrer ursprünglichen Frage und Anweisungen aus dem Abschnitt "Rolle & Verhalten" kombiniert. Diese Anweisungen, auch bekannt als Prompt, sind unser personalisierter Satz von Richtlinien für den Chatbot. Wenn wir möchten, dass der Chatbot immer einen Quellenlink am Ende seiner Antwort hinzufügt oder Benutzer auf eine bestimmte Weise begrüßt, fügen wir dies in den Prompt ein.
Dies erzeugt eine erweiterte Anfrage, die dann an das "Gehirn" des Chatbots – das Large Language Model (LLM) von OpenAI, Google oder anderen Anbietern – weitergegeben wird.
Das Sprachmodell analysiert diesen komplexen Satz von Informationen: den Prompt, die Gesprächshistorie und das für die Benutzeranfrage abgerufene Wissen. Zusätzlich nutzt das LLM sein allgemeines Weltwissen, um eine Antwort zu generieren. Dies ermöglicht hochgradig personalisierte Kundenerlebnisse mit KI. Schließlich wird die verfeinerte und polierte Antwort in der sauberen Oberfläche von ChatLab präsentiert.
Zusammenfassung
In diesem Artikel haben wir die Architektur des RAG-Systems in der Chatbot-Funktionalität durchlaufen – vom Dateneingang bis zur Antwortgenerierung. RAG ist eine grundlegende Komponente moderner Konversationssysteme, die eine effiziente Nutzung von externem Wissen ermöglicht. Unternehmen wie ChatLab integrieren diese bahnbrechende Technologie aktiv in ihre Produkte und bieten Kunden fortschrittliche und intelligente Interaktionsmöglichkeiten.
Obwohl das RAG-System eine gewisse technische Komplexität aufweist, ist sein Einfluss auf AI-generierten Text unbestreitbar. Die Tatsache, dass es von führenden Technologieunternehmen wie Google, Microsoft und Amazon erfolgreich eingesetzt wird, unterstreicht seine entscheidende Rolle in der dynamischen Entwicklung der künstlichen Intelligenz.
Bereit, die RAG-Technologie aus erster Hand zu erleben? Entdecken Sie die Funktionen von ChatLab oder erfahren Sie, wie Sie Ihren eigenen KI-Chatbot erstellen, der von dieser Technologie angetrieben wird.