Featured Posts



Jak ChatLab Wykorzystuje Technologię RAG?
April 18th, 2025 by Bartek Mularz

Jak ChatLab Wykorzystuje Technologię RAG?
W ChatLab tworzymy inteligentne chatboty, które rewolucjonizują interakcje online. Kluczowym elementem ich możliwości jest innowacyjna technologia zwana Retrieval-Augmented Generation (RAG). To ona stanowi fundament naszego systemu, umożliwiając nam dostarczanie rozwiązań wykraczających poza standardowe rozmowy.
W świecie chatbotów istnieją dwie główne metody szkolenia. Zrozumienie różnych typów chatbotów pomoże Ci zobaczyć, jak różnią się te podejścia szkoleniowe. Pierwsza polega na intensywnym szkoleniu złożonych sieci neuronowych—procesie skomplikowanym, czasochłonnym i kosztownym. Drugi sposób, który z powodzeniem stosujemy w ChatLab, to RAG. Nie tylko jest prostszy, tańszy i szybszy do wdrożenia, ale także daje naszym chatbotom dostęp do nieograniczonych zewnętrznych źródeł informacji—takich jak Twoje własne pliki. Dzięki temu możemy generować odpowiedzi, które są niezwykle precyzyjne, świadome kontekstu i spersonalizowane.
Zachęcamy do dalszej lektury, aby zgłębić, jak technologia RAG napędza ChatLab!
Czym dokładnie jest RAG?
Aby zrozumieć, jak działa nasz system, warto przyjrzeć się bliżej Retrieval-Augmented Generation. Choć interakcja z chatbotem może wydawać się intuicyjna z perspektywy użytkownika, zrozumienie mechanizmów jego działania pozwala w pełni docenić jego potencjał.
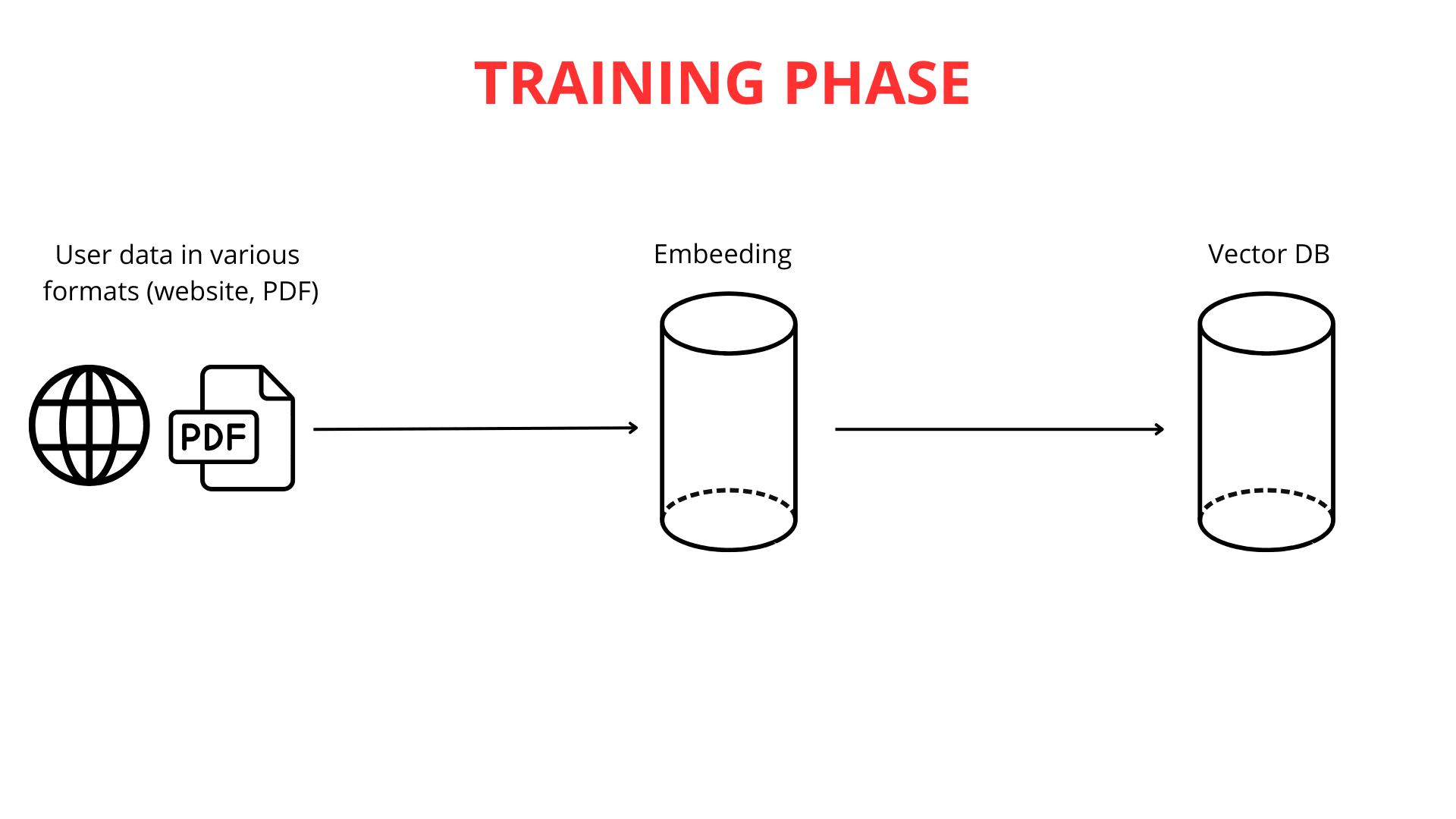
Budowanie inteligentnego chatbota to proces oparty na wiedzy z wielu dyscyplin naukowych. Pierwszym i najważniejszym krokiem jest dostarczanie chatbotowi danych. W ChatLab umożliwiamy to na kilka wygodnych sposobów: poprzez przesyłanie treści ze stron internetowych, obszernej dokumentacji, a nawet własnych plików PDF. Możliwości dostosowania bazy wiedzy do Twoich potrzeb są praktycznie nieograniczone.
Kolejnym etapem jest rozbicie długich tekstów na mniejsze fragmenty (do 600 tokenów każdy), co ułatwia systemowi efektywne przetwarzanie informacji. Po przesłaniu i podzieleniu danych rozpoczyna się proces mapowania wektorowego.
Warto podkreślić, że mapowanie tekstu na wektory jest kluczowe dla funkcjonalności RAG. Potężne silniki dużych modeli językowych (LLM) są odpowiedzialne za generowanie tych reprezentacji wektorowych.
Rola Mapowania Wektorowego w Zrozumieniu Tekstu
Wektoryzacja tekstu to zasadniczo przekształcanie słów w listy liczb—skonstruowane w taki sposób, że słowa o podobnym znaczeniu otrzymują podobne reprezentacje numeryczne (wektory). Dzięki temu nasz chatbot może "rozumieć" relacje między różnymi sekwencjami słów. Na przykład, słowa "duży" i "ogromny" zostaną przekształcone w bardzo podobne listy numeryczne, podczas gdy "duży" i "mrówka" otrzymają zupełnie inne reprezentacje.
Analizując te numeryczne podobieństwa i różnice, chatbot może wywnioskować, że "kot" i "pies" są bardziej ze sobą powiązane niż "kot" i "zielony".
Po wygenerowaniu wektorów, te numeryczne reprezentacje wiedzy są przechowywane w bazie danych wektorów wraz z oryginalną treścią. Baza danych wektorów działa jako zaawansowany katalog zwektorowanej wiedzy, zoptymalizowany do szybkiego wyszukiwania powiązanych znaczeń.
Baza Danych Wektorów: Inteligentna Biblioteka Wiedzy
Aby lepiej zrozumieć, jak działa baza danych wektorów, użyjmy analogii do biblioteki z inteligentnym systemem wyszukiwania. Każda "książka" (fragment tekstu) jest "oznaczona" unikalnym wektorem (ciągiem liczb). Ten kod zawiera wiele liczb reprezentujących autora, styl i tematykę książki. Dwie książki na podobne tematy będą miały bardzo podobne kody.
W tej "bibliotece" książki są umieszczane na "półkach" w przestrzeni wielowymiarowej na podstawie ich kodów. Książki o podobnych kodach są grupowane blisko siebie—podobnie jak książki w tej samej kategorii, ale dodatkowo zorganizowane według subtelnych podobieństw treści. Gdy zadajesz pytanie (np. "Jaki jest przepis na ciasto czekoladowe?"), jest ono przekształcane w taki "kod". Inteligentny system wyszukiwania w bazie danych wektorów przeszukuje "półki" (fragmenty tekstu) w poszukiwaniu kodów najbardziej zbliżonych do kodu Twojego zapytania.
Algorytm szybko identyfikuje "książki" (fragmenty), które najprawdopodobniej zawierają odpowiedź. Zamiast przeszukiwać całą "bibliotekę", chatbot natychmiast wskazuje najbardziej istotne fragmenty wiedzy pod względem znaczenia. To zapewnia szybsze, dokładniejsze i bardziej skoncentrowane na kontekście odpowiedzi.
Co się dzieje, gdy zadajesz pytanie?
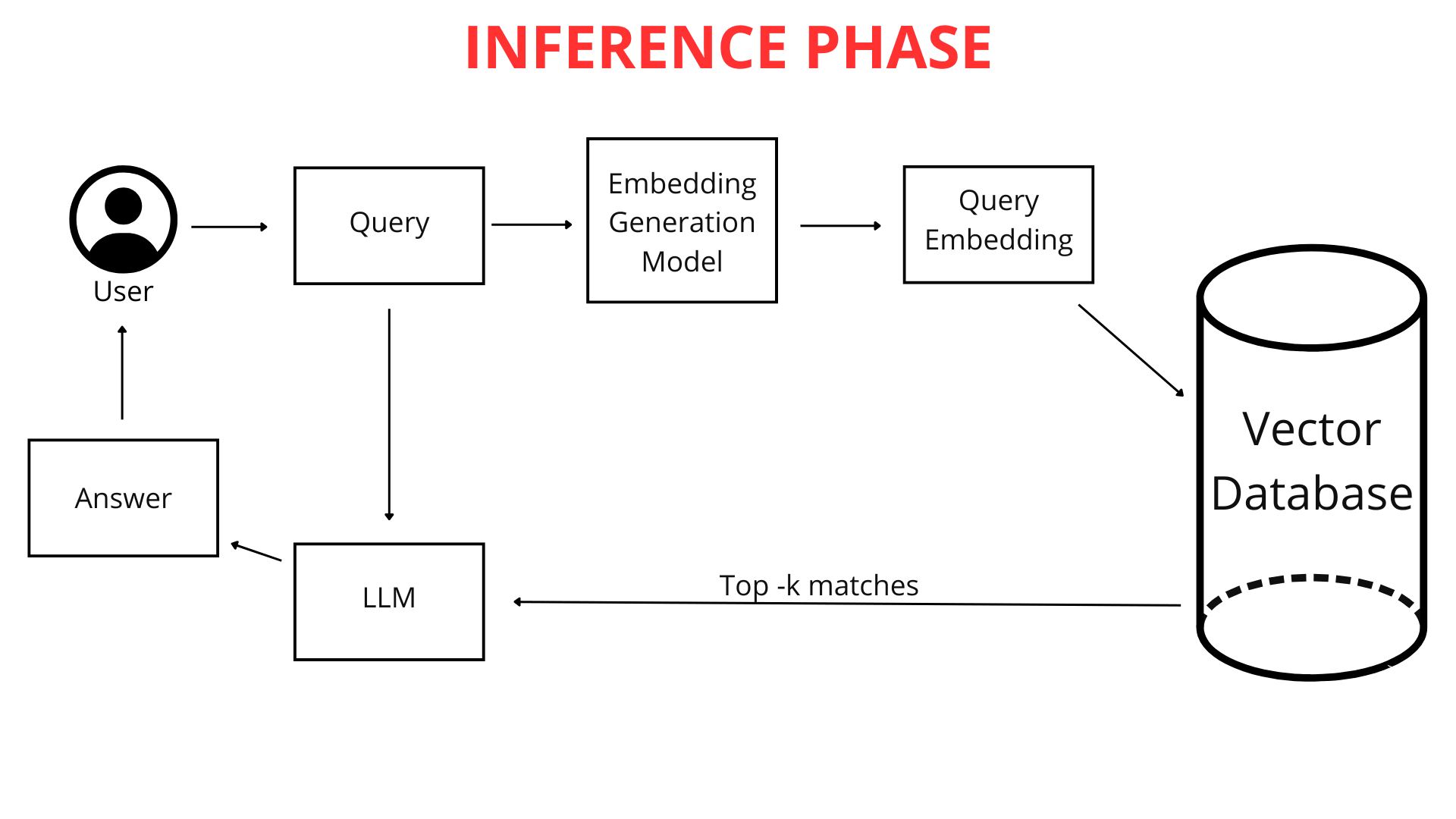
Gdy jako użytkownik wpisujesz pytanie do chatbota (np. "Jaka będzie pogoda w Krakowie jutro?"), nie jest ono od razu porównywane z wiedzą chatbota w surowej formie tekstowej. Najpierw pytanie jest mapowane na wektor numeryczny. Ponieważ zarówno Twoje pytanie, jak i cała baza wiedzy chatbota są reprezentowane w tym samym formacie—jako mapy wektorowe (listy liczb)—chatbot może efektywnie je porównywać. Identyfikuje fragmenty swojej wiedzy najbardziej zbliżone do wektora Twojego zapytania, co pozwala mu wygenerować najlepszą możliwą odpowiedź.
RAG Wkracza do Akcji
To właśnie tutaj technologia RAG odgrywa kluczową rolę. System RAG analizuje wektorową reprezentację Twojego zapytania i wykorzystuje ją do przeszukiwania bazy danych wektorów w poszukiwaniu list numerycznych najbardziej do niego podobnych (najbliższych w przestrzeni wielowymiarowej). Te najbardziej podobne wektory wskazują na oryginalne fragmenty plików najbardziej istotne dla Twojego pytania.
RAG działa jak inteligentny "most" między Twoim zapytaniem a rozległą bazą wiedzy chatbota. Umożliwia dynamiczne pobieranie tylko tych informacji, które są najbardziej potrzebne dla LLM (Large Language Model) do sformułowania odpowiedzi. LLM, w prostych słowach, to zaawansowany algorytm i zbiór danych szkolony na ogromnych ilościach tekstu, zdolny do rozumienia i generowania języka naturalnego. Aby dowiedzieć się więcej o tej technologii, sprawdź jak faktycznie działa ChatGPT. LLM mogą odpowiadać na pytania, a nawet tworzyć różnorodne treści.
Bez RAG, LLM musiałby polegać wyłącznie na swojej wbudowanej wiedzy, która może nie zawierać szczegółowych informacji z Twoich plików lub być nieaktualna. Dzięki RAG, chatbot zyskuje możliwość korzystania z dodatkowej zewnętrznej wiedzy dokładnie wtedy, gdy zadajesz pytanie. Ta świeża wiedza pochodzi bezpośrednio z Twoich przesłanych plików i stron internetowych, które zostały odpowiednio przetworzone.
Różnica między Chatbotem z RAG a bez RAG
Kluczowa różnica polega na sposobie dostępu do wiedzy.
Wiedza Szkolona (Bez RAG): To "wbudowana" wiedza LLM, zdobyta podczas intensywnego szkolenia na ogromnych zbiorach danych przed Twoją interakcją z ChatLab. Jeśli zapytasz o coś, co nie zostało uwzględnione w tych danych, model może po prostu nie znać odpowiedzi.
Wiedza z Twoich Plików (Używana przez RAG): To Twoja unikalna, specjalistyczna wiedza, którą dostarczasz chatbotowi. RAG pozwala chatbotowi dynamicznie uzyskiwać dostęp do tej wiedzy podczas odpowiadania na pytania, łącząc ją z ogólną wiedzą szkoleniową, aby wygenerować kompleksową odpowiedź. To podejście napędza nowoczesną konwersacyjną AI do obsługi klienta.
Analogicznie:
Wyobraź sobie LLM jako niezwykle inteligentnego ucznia, który przeczytał niezliczone książki (dane szkoleniowe) i posiada imponującą wiedzę ogólną. Teraz dostarczasz mu swoje notatki z wykładów i materiały (Twoje pliki). RAG działa jako system, który pozwala temu uczniowi szybko sprawdzić Twoje notatki podczas odpowiadania na pytanie, zamiast polegać wyłącznie na tym, co zapamiętał z tych wszystkich książek. To ulepszenie gwarantuje lepsze, bardziej precyzyjne i—co najważniejsze—bardziej aktualne odpowiedzi.
Dzięki RAG chatbot może rozszerzać swoją wiedzę o Twoje unikalne dane i aktywnie z nich korzystać w interakcjach. Nie jest ograniczony tylko do tego, czego nauczył się podczas początkowego szkolenia.
Dlatego RAG jest nieoceniony, gdy potrzebujesz, aby chatbot odpowiadał na pytania dotyczące Twoich specyficznych informacji—szczegółów, które nie są publicznie dostępne lub są zbyt niszowe, aby zostały uwzględnione w ogólnych danych szkoleniowych LLM.
Jeśli Twoje pytanie brzmi: "Gdzie mogę znaleźć książki o kosmosie?", zanim "bibliotekarz" (chatbot) zacznie "przeszukiwać półki", najpierw "tłumaczy" Twoje pytanie na "język półek"—identyfikując odpowiednią kategorię książek. Tworzenie mapy wektorowej Twojego pytania jest jak katalogowanie Twojego zapytania w kategoriach, które chatbot rozumie i do których ma dostęp za pomocą bazy danych wektorów.
Faza Szkolenia i Wykorzystania Wiedzy
Jak wyjaśniono wcześniej, Twoje pytanie jest przekształcane w listę liczb reprezentujących jego znaczenie. Chatbot następnie przeszukuje bazę danych wektorów w poszukiwaniu najbardziej podobnych wektorów reprezentujących fragmenty wiedzy. Im bliższe są reprezentacje wektorowe, tym większe podobieństwo między Twoim pytaniem a tymi fragmentami wiedzy.
Chatbot wybiera najbardziej pasujące fragmenty swojej przetworzonej wiedzy—te, których wektory są najbliższe mapie wektorowej Twojego pytania. Co ważne, analizując Twoje zapytanie, ChatLab bierze pod uwagę nie tylko samo pytanie, ale także kontekst całej dotychczasowej rozmowy. To pozwala systemowi RAG bardziej precyzyjnie wybierać najlepsze informacje z powiązanych źródeł wiedzy.
Na przykład, jeśli najpierw zapytasz o "najnowsze modele telefonów", a następnie zapytasz "Czy mają dobre aparaty?", chatbot—pamiętając kontekst rozmowy—rozumie, że nadal odnosisz się do tych konkretnych telefonów.
Wybrane fragmenty wiedzy są łączone z Twoim oryginalnym pytaniem i instrukcjami z sekcji "Rola i Zachowanie". Te instrukcje, znane również jako prompt, to nasz spersonalizowany zestaw wytycznych dla chatbota. Jeśli chcemy, aby chatbot zawsze dodawał link do źródła na końcu swojej odpowiedzi lub witał użytkowników w określony sposób, uwzględniamy to w prompt.
To tworzy wzbogacone zapytanie, które następnie jest przekazywane do "mózgu" chatbota—dużego modelu językowego (LLM) od OpenAI, Google lub innych dostawców.
Model językowy analizuje ten złożony zestaw informacji: prompt, historię rozmowy oraz wiedzę pobraną dla zapytania użytkownika. Dodatkowo, LLM wykorzystuje swoją ogólną wiedzę o świecie, aby wygenerować odpowiedź. To umożliwia wysoce spersonalizowane doświadczenia klientów z AI. Ostatecznie, dopracowana i wygładzona odpowiedź jest prezentowana w czystym interfejsie ChatLab.
Podsumowanie
W tym artykule przeszliśmy przez architekturę systemu RAG w funkcjonalności chatbotów—od wprowadzenia danych po generowanie odpowiedzi. RAG jest fundamentalnym elementem nowoczesnych systemów konwersacyjnych, umożliwiającym efektywne wykorzystanie zewnętrznej wiedzy. Firmy takie jak ChatLab aktywnie integrują tę przełomową technologię w swoich produktach, dostarczając klientom zaawansowane i inteligentne możliwości interakcji.
Choć system RAG ma pewną złożoność techniczną, jego wpływ na tekst generowany przez AI jest niezaprzeczalny. Fakt, że jest z powodzeniem wykorzystywany przez wiodące firmy technologiczne, takie jak Google, Microsoft i Amazon, podkreśla jego kluczową rolę w dynamicznej ewolucji sztucznej inteligencji.
Gotowy do doświadczenia technologii RAG osobiście? Poznaj funkcje ChatLab lub dowiedz się jak zbudować własnego chatbota AI opartego na tej technologii.