Featured Posts



¿Cómo Aprovecha ChatLab la Tecnología RAG?
April 18th, 2025 by Bartek Mularz

¿Cómo Aprovecha ChatLab la Tecnología RAG?
En ChatLab, creamos chatbots inteligentes que revolucionan las interacciones en línea. El motor clave detrás de sus capacidades es una tecnología innovadora llamada Generación Aumentada por Recuperación (RAG). Esta forma la base de nuestro sistema, permitiéndonos ofrecer soluciones que van más allá de las conversaciones estándar.
En el mundo de los chatbots, existen dos métodos principales de entrenamiento. Comprender los diferentes tipos de chatbots te ayuda a ver cómo difieren estos enfoques de entrenamiento. El primero implica un entrenamiento intensivo de redes neuronales complejas, un proceso intrincado, que consume tiempo y es costoso. El segundo enfoque, que empleamos exitosamente en ChatLab, es RAG. No solo es más simple, rentable y rápido de implementar, sino que también otorga a nuestros chatbots acceso a fuentes externas de información ilimitadas, como tus propios archivos. Esto nos permite generar respuestas altamente precisas, conscientes del contexto y personalizadas.
Te invitamos a seguir leyendo y profundizar en cómo la tecnología RAG impulsa ChatLab.
¿Qué es exactamente RAG?
Para entender cómo funciona nuestro sistema, vale la pena echar un vistazo más de cerca a la Generación Aumentada por Recuperación. Aunque interactuar con un chatbot puede parecer intuitivo desde la perspectiva del usuario, comprender los mecanismos detrás de su operación te permite apreciar completamente su potencial.
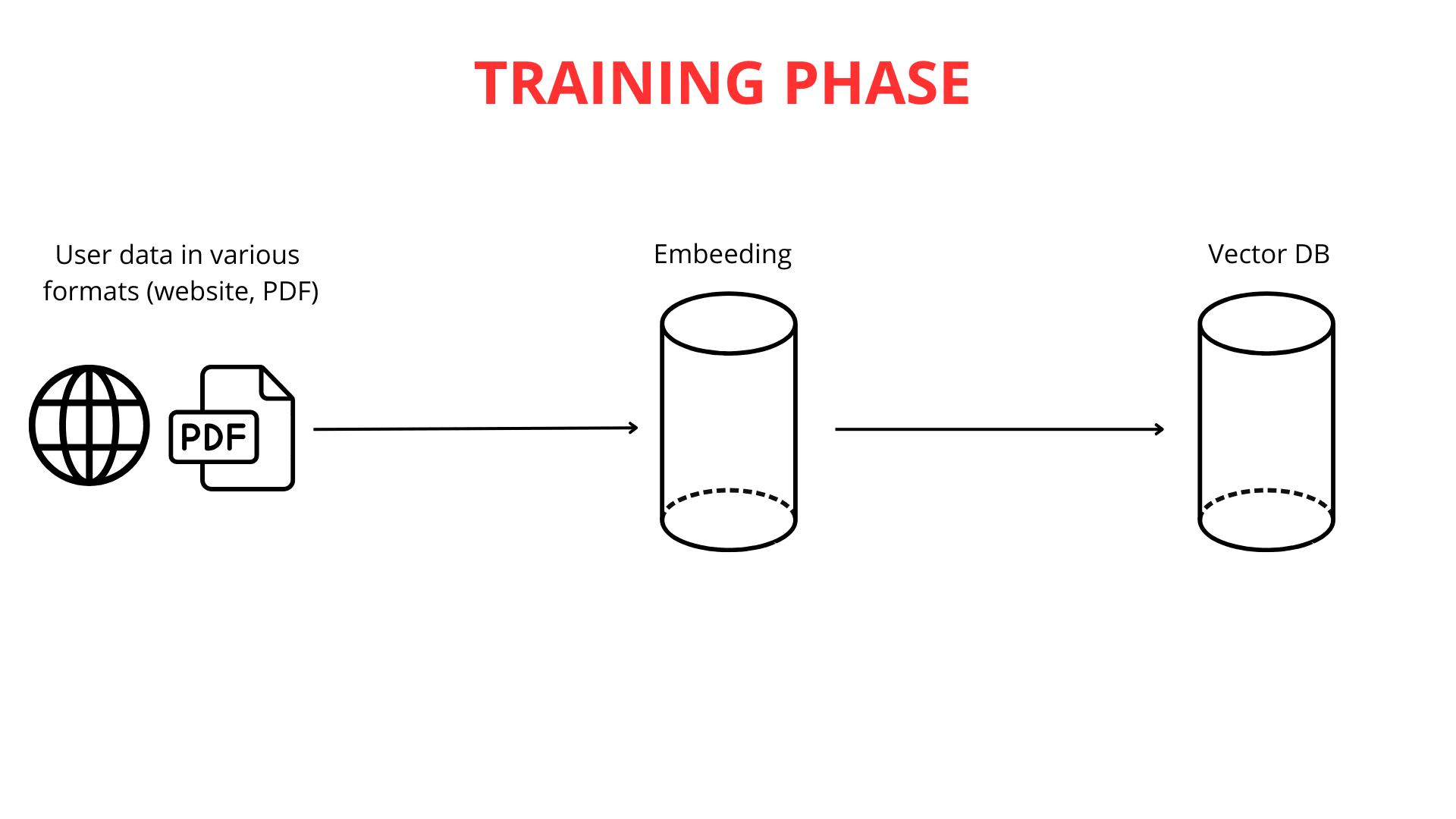
Construir un chatbot inteligente es un proceso arraigado en el conocimiento de múltiples disciplinas científicas. El primer y más crucial paso es alimentar al chatbot con datos. En ChatLab, habilitamos esto de varias maneras convenientes: cargando contenido de sitios web, documentación extensa o incluso tus propios archivos PDF. Las posibilidades para personalizar la base de conocimiento según tus necesidades son prácticamente ilimitadas.
La siguiente etapa implica descomponer textos largos en fragmentos más pequeños (hasta 600 tokens cada uno), facilitando que el sistema procese la información de manera eficiente. Una vez que los datos se cargan y segmentan, comienza el proceso de mapeo vectorial.
Es importante enfatizar que el mapeo de texto a vector es crítico para la funcionalidad de RAG. Potentes motores de modelos de lenguaje grande (LLM) son responsables de generar estas representaciones vectoriales.
El Papel del Mapeo Vectorial en la Comprensión del Texto
La vectorización del texto es esencialmente convertir palabras en listas de números, construidas de tal manera que palabras con significados similares reciban representaciones numéricas similares (vectores). Esto permite que nuestro chatbot "entienda" las relaciones entre diferentes secuencias de palabras. Por ejemplo, las palabras "grande" y "enorme" se transformarían en listas numéricas muy similares, mientras que "grande" y "hormiga" recibirían representaciones completamente diferentes.
Al analizar estas similitudes y diferencias numéricas, el chatbot puede inferir que "gato" y "perro" están más relacionados que "gato" y "verde".
Una vez que se generan los vectores, estas representaciones numéricas del conocimiento se almacenan en una base de datos vectorial junto con el contenido original. La base de datos vectorial actúa como un catálogo avanzado de conocimiento vectorizado, optimizado para la recuperación rápida de significados relacionados.
La Base de Datos Vectorial: Una Biblioteca de Conocimiento Inteligente
Para entender mejor cómo funciona una base de datos vectorial, usemos la analogía de una biblioteca con un sistema de búsqueda inteligente. Cada "libro" (fragmento de texto) está "etiquetado" por un vector único (una secuencia de números). Este código contiene múltiples números que representan al autor, estilo y tema del libro. Dos libros sobre temas similares tendrán códigos muy similares.
En esta "biblioteca", los libros se colocan en "estantes" en un espacio multidimensional basado en sus códigos. Los libros con códigos similares se agrupan cerca unos de otros, al igual que los libros en la misma categoría, pero organizados además por similitudes sutiles de contenido. Cuando haces una pregunta (por ejemplo, "¿Cuál es la receta del pastel de chocolate?"), se convierte en tal "código". El sistema de búsqueda inteligente en la base de datos vectorial escanea los "estantes" (fragmentos de texto) en busca de los códigos que más se asemejan al código de tu consulta.
El algoritmo identifica rápidamente los "libros" (fragmentos) más propensos a contener la respuesta. En lugar de buscar en toda la "biblioteca", el chatbot señala instantáneamente las piezas de conocimiento más relevantes en términos de significado. Esto asegura respuestas más rápidas, precisas y enfocadas en el contexto.
¿Qué Sucede Cuando Haces una Pregunta?
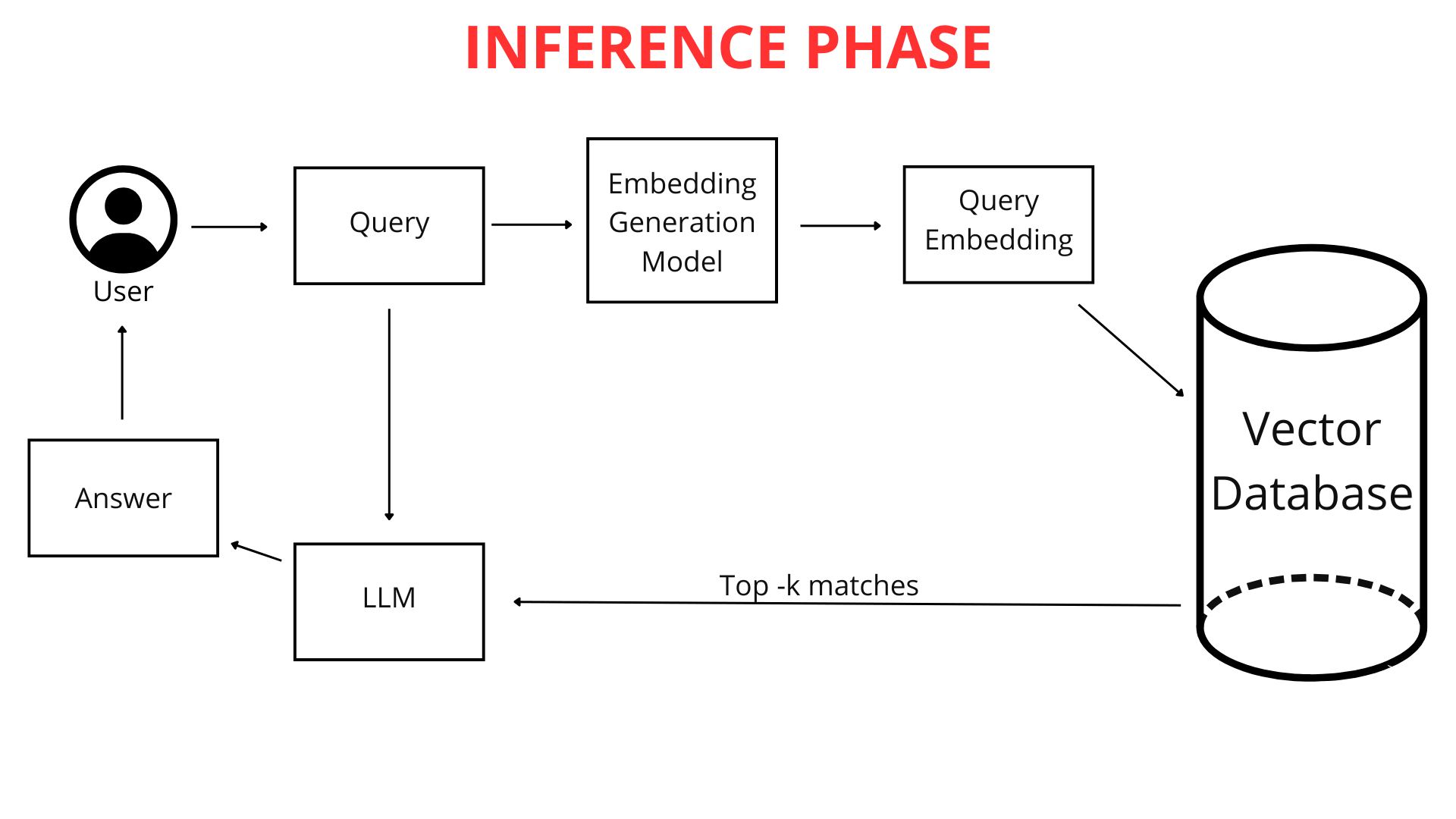
Cuando tú, como usuario, escribes una pregunta en el chatbot (por ejemplo, "¿Cuál es el clima en Cracovia mañana?"), no se compara inmediatamente con el conocimiento del chatbot en forma de texto bruto. Primero, la pregunta se mapea en un vector numérico. Debido a que tanto tu pregunta como toda la base de conocimiento del chatbot están representadas en el mismo formato, como mapas vectoriales (listas de números), el chatbot puede compararlos eficientemente. Identifica los fragmentos de su conocimiento más relacionados con el vector de tu consulta, permitiéndole generar la mejor respuesta posible.
RAG Entra en Acción
Aquí es donde la tecnología RAG juega un papel crucial. El sistema RAG analiza la representación vectorial de tu consulta y la utiliza para buscar en la base de datos vectorial las listas numéricas más similares a ella (las más cercanas en el espacio multidimensional). Estos vectores más similares apuntan a los fragmentos de archivo originales más relevantes para tu pregunta.
RAG actúa como un "puente" inteligente entre tu consulta y la vasta base de conocimiento del chatbot. Permite la recuperación dinámica de solo la información más necesaria para que el LLM (Modelo de Lenguaje Grande) formule una respuesta. Un LLM, en términos simples, es un algoritmo avanzado y un conjunto de datos entrenado en grandes cantidades de texto, capaz de entender y generar lenguaje natural. Para aprender más sobre esta tecnología, consulta cómo funciona realmente ChatGPT. Los LLM pueden responder preguntas e incluso crear contenido diverso.
Sin RAG, un LLM tendría que depender únicamente de su conocimiento incorporado, que podría no incluir detalles específicos de tus archivos o podría estar desactualizado. Gracias a RAG, el chatbot adquiere la capacidad de acceder a conocimiento externo adicional precisamente cuando haces una pregunta. Este conocimiento fresco proviene directamente de tus archivos y páginas web cargados, que han sido procesados adecuadamente.
La Diferencia Entre un Chatbot Con y Sin RAG
La diferencia clave está en cómo se accede al conocimiento.
Conocimiento Entrenado (Sin RAG): Este es el conocimiento "incorporado" del LLM, adquirido durante un entrenamiento intensivo en grandes conjuntos de datos antes de tu interacción con ChatLab. Si preguntas sobre algo que no está cubierto en esos datos, el modelo puede simplemente no saber la respuesta.
Conocimiento de Tus Archivos (Usado a través de RAG): Este es tu conocimiento único y especializado que proporcionas al chatbot. RAG permite que el chatbot acceda dinámicamente a este conocimiento al responder preguntas, combinándolo con su conocimiento de entrenamiento general para generar una respuesta completa. Este enfoque impulsa la moderna IA conversacional para el servicio al cliente.
Una Analogía:
Imagina un LLM como un estudiante extremadamente inteligente que ha leído innumerables libros (datos de entrenamiento) y posee un impresionante conocimiento general. Ahora, le proporcionas tus apuntes de clase y folletos (tus archivos). RAG actúa como un sistema que permite a este estudiante revisar rápidamente tus apuntes al responder una pregunta, en lugar de depender únicamente de lo que recuerda de todos esos libros. Esta mejora garantiza respuestas mejores, más precisas y, lo más importante, más actualizadas.
Gracias a RAG, el chatbot puede expandir su conocimiento con tus datos únicos y usarlos activamente en las interacciones. No está limitado solo a lo que aprendió durante su entrenamiento inicial.
Por eso RAG es invaluable cuando necesitas que un chatbot responda preguntas sobre tu información específica, detalles que no están disponibles públicamente o son demasiado especializados para ser incluidos en los datos de entrenamiento general de un LLM.
Si tu pregunta es: "¿Dónde puedo encontrar libros sobre el espacio?", antes de que el "bibliotecario" (chatbot) comience a "buscar en los estantes", primero "traduce" tu pregunta al "lenguaje de los estantes", identificando la categoría de libro adecuada. Crear un mapa vectorial de tu pregunta es como catalogar tu consulta en categorías que el chatbot entiende y puede acceder a través de la base de datos vectorial.
La Fase de Entrenamiento y Utilización del Conocimiento
Como se explicó anteriormente, tu pregunta se convierte en una lista de números que representa su significado. El chatbot luego busca en la base de datos vectorial los vectores más similares que representan fragmentos de conocimiento. Cuanto más cercanas sean las representaciones vectoriales, mayor será la similitud entre tu pregunta y esos fragmentos de conocimiento.
El chatbot selecciona los fragmentos de conocimiento preprocesados que más se asemejan, aquellos cuyos vectores están más cerca del mapa vectorial de tu pregunta. Es importante destacar que, al analizar tu consulta, ChatLab considera no solo la pregunta en sí, sino también el contexto de toda la conversación hasta el momento. Esto permite que el sistema RAG seleccione más precisamente la mejor información de las fuentes de conocimiento conectadas.
Por ejemplo, si primero preguntas sobre "los últimos modelos de teléfonos" y luego sigues con "¿Tienen buenas cámaras?", el chatbot, recordando el contexto de la conversación, entiende que todavía te refieres a esos teléfonos específicos.
Los fragmentos de conocimiento seleccionados se combinan con tu pregunta original e instrucciones de la sección "Rol y Comportamiento". Estas instrucciones, también conocidas como el prompt, son nuestro conjunto personalizado de pautas para el chatbot. Si queremos que el chatbot siempre agregue un enlace de fuente al final de su respuesta o salude a los usuarios de una manera específica, lo incluimos en el prompt.
Esto crea una consulta aumentada, que luego se pasa al "cerebro" del chatbot, el modelo de lenguaje grande (LLM) de OpenAI, Google u otros proveedores.
El modelo de lenguaje analiza este conjunto complejo de información: el prompt, el historial de la conversación y el conocimiento recuperado para la consulta del usuario. Además, el LLM aprovecha su conocimiento general del mundo para generar una respuesta. Esto permite experiencias de cliente altamente personalizadas con IA. Finalmente, la respuesta refinada y pulida se presenta en la interfaz limpia de ChatLab.
Resumen
En este artículo, hemos recorrido la arquitectura del sistema RAG en la funcionalidad del chatbot, desde la entrada de datos hasta la generación de respuestas. RAG es un componente fundamental de los sistemas conversacionales modernos, permitiendo el uso eficiente del conocimiento externo. Empresas como ChatLab integran activamente esta tecnología innovadora en sus productos, ofreciendo capacidades de interacción avanzadas e inteligentes a los clientes.
Aunque el sistema RAG tiene cierta complejidad técnica, su impacto en el texto generado por IA es innegable. El hecho de que sea utilizado exitosamente por empresas tecnológicas líderes como Google, Microsoft y Amazon subraya su papel fundamental en la evolución dinámica de la inteligencia artificial.
¿Listo para experimentar la tecnología RAG de primera mano? Explora las funciones de ChatLab o aprende cómo construir tu propio chatbot de IA impulsado por esta tecnología.