Featured Posts



Comment ChatLab Exploite la Technologie RAG ?
April 18th, 2025 by Bartek Mularz

Comment ChatLab Exploite la Technologie RAG ?
Chez ChatLab, nous créons des chatbots intelligents qui révolutionnent les interactions en ligne. Le moteur de leurs capacités est une technologie innovante appelée Génération Augmentée par Récupération (RAG). Cela forme la base de notre système, nous permettant de fournir des solutions qui vont au-delà des conversations standard.
Dans le monde des chatbots, il existe deux principales méthodes d'entraînement. Comprendre les différents types de chatbots vous aide à voir comment ces approches d'entraînement diffèrent. La première implique un entraînement intensif de réseaux neuronaux complexes—un processus complexe, chronophage et coûteux. La deuxième approche, que nous utilisons avec succès chez ChatLab, est RAG. Non seulement elle est plus simple, plus économique et plus rapide à mettre en œuvre, mais elle permet également à nos chatbots d'accéder à des sources d'information externes illimitées—comme vos propres fichiers. Cela nous permet de générer des réponses très précises, contextuelles et personnalisées.
Nous vous invitons à continuer votre lecture pour explorer plus en profondeur comment la technologie RAG alimente ChatLab !
Qu'est-ce que le RAG exactement ?
Pour comprendre comment fonctionne notre système, il vaut la peine de se pencher de plus près sur la Génération Augmentée par Récupération. Bien qu'interagir avec un chatbot puisse sembler intuitif du point de vue de l'utilisateur, comprendre les mécanismes derrière son fonctionnement vous permet d'apprécier pleinement son potentiel.
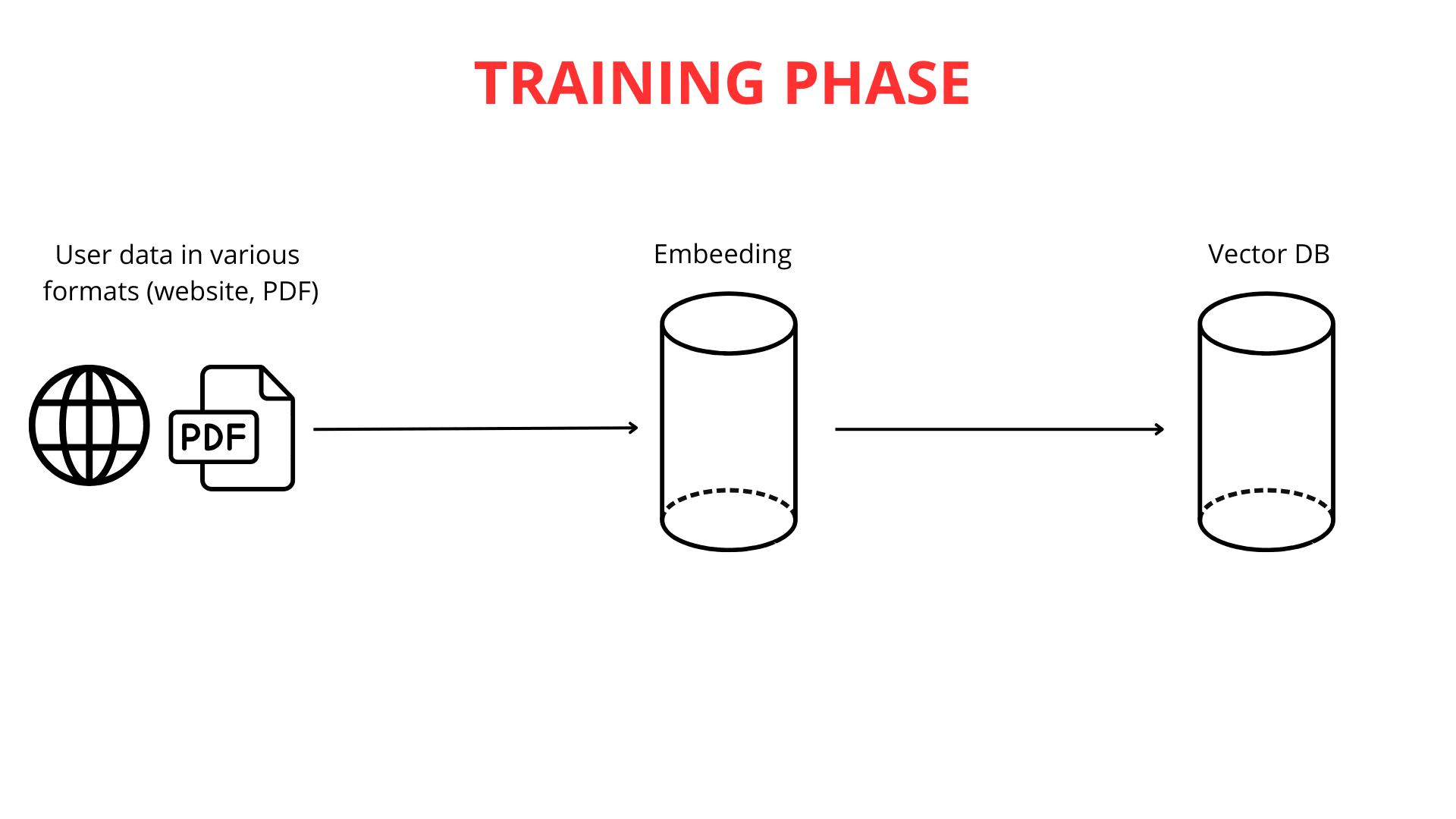
Construire un chatbot intelligent est un processus ancré dans des connaissances issues de multiples disciplines scientifiques. La première étape, et la plus cruciale, est d'alimenter le chatbot en données. Chez ChatLab, nous permettons cela de plusieurs manières pratiques : en téléchargeant le contenu de sites web, une documentation extensive, ou même vos propres fichiers PDF. Les possibilités de personnaliser la base de connaissances selon vos besoins sont pratiquement illimitées.
La prochaine étape consiste à décomposer les longs textes en morceaux plus petits (jusqu'à 600 tokens chacun), ce qui facilite le traitement efficace de l'information par le système. Une fois les données téléchargées et segmentées, le processus de mappage vectoriel commence.
Il est important de souligner que le mappage texte-vers-vecteur est crucial pour le fonctionnement du RAG. De puissants moteurs de modèles de langage de grande taille (LLM) sont responsables de la génération de ces représentations vectorielles.
Le Rôle du Mappage Vectoriel dans la Compréhension du Texte
La vectorisation du texte consiste essentiellement à convertir des mots en listes de nombres—construites de manière à ce que les mots ayant des significations similaires reçoivent des représentations numériques similaires (vecteurs). Cela permet à notre chatbot de "comprendre" les relations entre différentes séquences de mots. Par exemple, les mots "grand" et "énorme" seraient transformés en listes numériques très similaires, tandis que "grand" et "fourmi" recevraient des représentations entièrement différentes.
En analysant ces similitudes et différences numériques, le chatbot peut déduire que "chat" et "chien" sont plus étroitement liés que "chat" et "vert".
Une fois les vecteurs générés, ces représentations numériques de la connaissance sont stockées dans une base de données vectorielle aux côtés du contenu original. La base de données vectorielle agit comme un catalogue avancé de connaissances vectorisées, optimisé pour une récupération rapide des significations connexes.
La Base de Données Vectorielle : Une Bibliothèque de Connaissances Intelligente
Pour mieux comprendre comment fonctionne une base de données vectorielle, utilisons l'analogie d'une bibliothèque avec un système de recherche intelligent. Chaque "livre" (fragment de texte) est "étiqueté" par un vecteur unique (une séquence de nombres). Ce code contient plusieurs nombres représentant l'auteur, le style et le sujet du livre. Deux livres sur des sujets similaires auront des codes très similaires.
Dans cette "bibliothèque", les livres sont placés sur des "étagères" dans un espace multidimensionnel basé sur leurs codes. Les livres avec des codes similaires sont regroupés ensemble—un peu comme des livres dans la même catégorie mais organisés plus finement par des similitudes de contenu subtiles. Lorsque vous posez une question (par exemple, "Quelle est la recette du gâteau au chocolat ?"), elle est convertie en un tel "code". Le système de recherche intelligent dans la base de données vectorielle scanne les "étagères" (fragments de texte) pour trouver les codes correspondant le plus à celui de votre requête.
L'algorithme identifie rapidement les "livres" (fragments) les plus susceptibles de contenir la réponse. Au lieu de rechercher dans toute la "bibliothèque", le chatbot identifie instantanément les morceaux de connaissance les plus pertinents en termes de signification. Cela garantit des réponses plus rapides, plus précises et axées sur le contexte.
Que se Passe-t-il Lorsque Vous Posez une Question ?
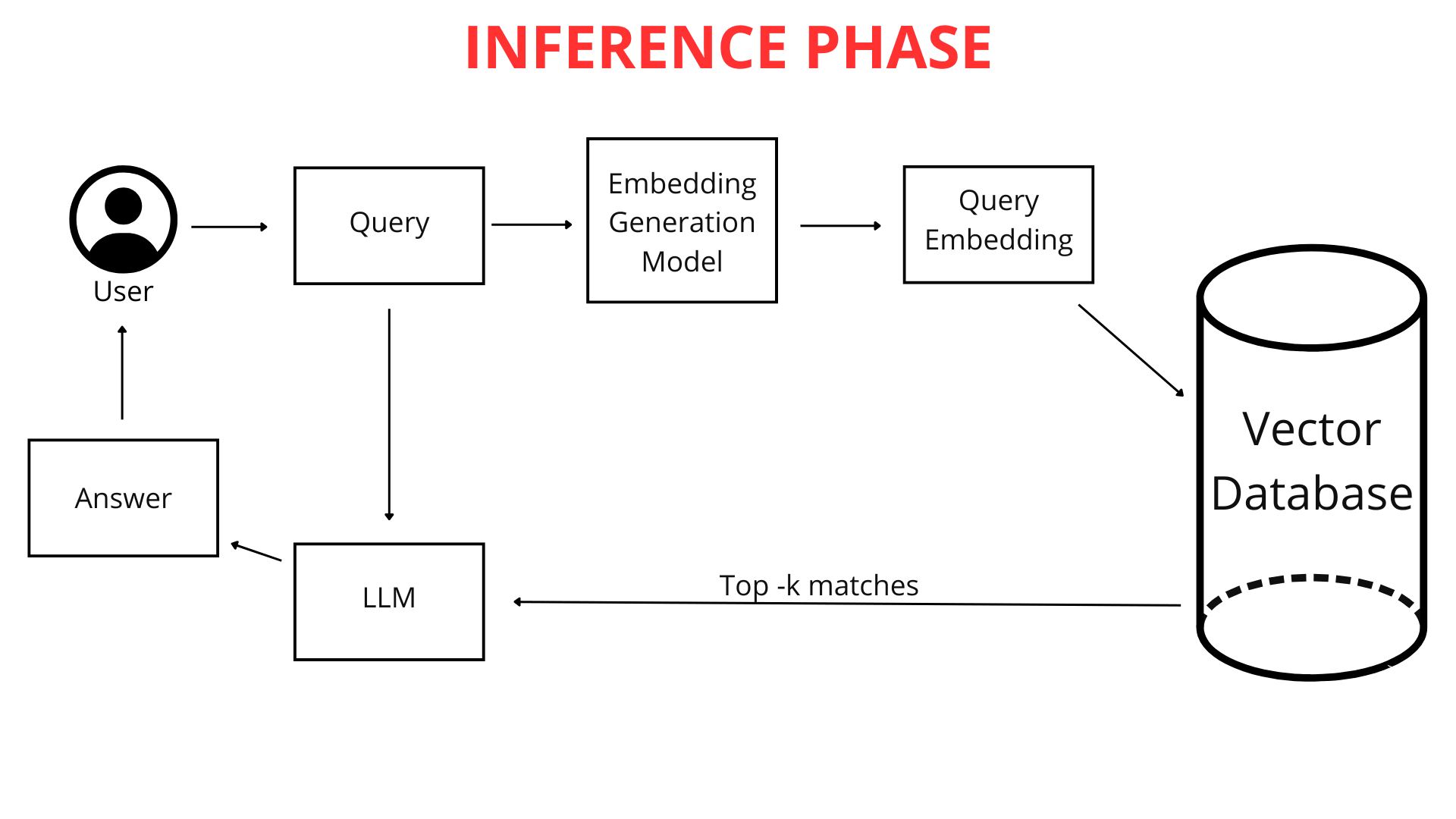
Lorsque vous, en tant qu'utilisateur, tapez une question dans le chatbot (par exemple, "Quel temps fera-t-il à Cracovie demain ?"), elle n'est pas immédiatement comparée à la connaissance du chatbot sous forme de texte brut. Tout d'abord, la question est mappée en un vecteur numérique. Parce que votre question et l'ensemble de la base de connaissances du chatbot sont représentées dans le même format—sous forme de cartes vectorielles (listes de nombres)—le chatbot peut les comparer efficacement. Il identifie les fragments de sa connaissance les plus étroitement liés au vecteur de votre requête, lui permettant de générer la meilleure réponse possible.
RAG Entre en Action
C'est ici que la technologie RAG joue un rôle crucial. Le système RAG analyse la représentation vectorielle de votre requête et l'utilise pour rechercher dans la base de données vectorielle les listes numériques les plus similaires (les plus proches dans l'espace multidimensionnel). Ces vecteurs les plus similaires pointent vers les fragments de fichiers originaux les plus pertinents pour votre question.
RAG agit comme un "pont" intelligent entre votre requête et la vaste base de connaissances du chatbot. Il permet la récupération dynamique de seulement l'information la plus nécessaire pour que le LLM (Modèle de Langage de Grande Taille) formule une réponse. Un LLM, en termes simples, est un algorithme avancé et un ensemble de données entraîné sur d'énormes quantités de texte, capable de comprendre et de générer un langage naturel. Pour en savoir plus sur cette technologie, consultez comment ChatGPT fonctionne réellement. Les LLM peuvent répondre à des questions et même créer divers contenus.
Sans RAG, un LLM devrait se fier uniquement à sa connaissance intégrée, qui pourrait ne pas inclure des détails spécifiques de vos fichiers ou pourrait être obsolète. Grâce à RAG, le chatbot acquiert la capacité de puiser dans des connaissances externes supplémentaires précisément lorsque vous posez une question. Ces nouvelles connaissances proviennent directement de vos fichiers et pages web téléchargés, qui ont été correctement traités.
La Différence Entre un Chatbot Avec et Sans RAG
La différence clé réside dans la manière dont la connaissance est accessible.
Connaissance Entraînée (Sans RAG) : C'est la connaissance "intégrée" du LLM, acquise lors d'un entraînement intensif sur d'énormes ensembles de données avant votre interaction avec ChatLab. Si vous posez une question sur quelque chose qui n'est pas couvert dans ces données, le modèle peut simplement ne pas connaître la réponse.
Connaissance de Vos Fichiers (Utilisée via RAG) : C'est votre connaissance unique et spécialisée que vous fournissez au chatbot. RAG permet au chatbot d'accéder dynamiquement à cette connaissance lors de la réponse aux questions, en la combinant avec sa connaissance générale d'entraînement pour générer une réponse complète. Cette approche alimente l'IA conversationnelle moderne pour le service client.
Une Analogie :
Imaginez un LLM comme un étudiant extrêmement intelligent qui a lu d'innombrables livres (données d'entraînement) et possède une connaissance générale impressionnante. Maintenant, vous lui fournissez vos notes de cours et documents (vos fichiers). RAG agit comme un système qui permet à cet étudiant de vérifier rapidement vos notes lorsqu'il répond à une question, plutôt que de se fier uniquement à ce qu'il se souvient de tous ces livres. Cette amélioration garantit des réponses meilleures, plus précises et—surtout—plus à jour.
Grâce à RAG, le chatbot peut étendre sa connaissance avec vos données uniques et les utiliser activement dans les interactions. Il n'est pas limité uniquement à ce qu'il a appris lors de son entraînement initial.
C'est pourquoi RAG est inestimable lorsque vous avez besoin qu'un chatbot réponde à des questions sur vos informations spécifiques—des détails qui ne sont pas publiquement disponibles ou trop spécifiques pour être inclus dans les données d'entraînement générales des LLM.
Si votre question est : "Où puis-je trouver des livres sur l'espace ?", avant que le "bibliothécaire" (chatbot) ne commence à "chercher sur les étagères", il "traduit" d'abord votre question dans le "langage des étagères"—identifiant la catégorie de livre appropriée. Créer une carte vectorielle de votre question revient à cataloguer votre requête dans des catégories que le chatbot comprend et peut accéder via la base de données vectorielle.
La Phase d'Entraînement et d'Utilisation des Connaissances
Comme expliqué précédemment, votre question est convertie en une liste de nombres représentant sa signification. Le chatbot recherche ensuite dans la base de données vectorielle les vecteurs les plus similaires représentant des fragments de connaissance. Plus les représentations vectorielles sont proches, plus la similitude entre votre question et ces fragments de connaissance est grande.
Le chatbot sélectionne les fragments de connaissance prétraités les plus proches—ceux dont les vecteurs sont les plus proches de la carte vectorielle de votre question. Il est important de noter que lors de l'analyse de votre requête, ChatLab prend en compte non seulement la question elle-même mais aussi le contexte de toute la conversation jusqu'à présent. Cela permet au système RAG de sélectionner plus précisément la meilleure information à partir des sources de connaissance connectées.
Par exemple, si vous demandez d'abord "les derniers modèles de téléphones" puis enchaînez avec "Ont-ils de bons appareils photo ?", le chatbot—se souvenant du contexte de la conversation—comprend que vous parlez toujours de ces téléphones spécifiques.
Les fragments de connaissance sélectionnés sont combinés avec votre question originale et les instructions de la section "Rôle & Comportement". Ces instructions, également connues sous le nom de prompt, sont notre ensemble personnalisé de directives pour le chatbot. Si nous voulons que le chatbot ajoute toujours un lien source à la fin de sa réponse ou salue les utilisateurs d'une manière spécifique, nous l'incluons dans le prompt.
Cela crée une requête augmentée, qui est ensuite transmise au "cerveau" du chatbot—le modèle de langage de grande taille (LLM) d'OpenAI, Google ou d'autres fournisseurs.
Le modèle de langage analyse cet ensemble complexe d'informations : le prompt, l'historique de la conversation et la connaissance récupérée pour la requête de l'utilisateur. De plus, le LLM utilise sa connaissance générale du monde pour générer une réponse. Cela permet des expériences client hautement personnalisées avec l'IA. Enfin, la réponse affinée et polie est présentée dans l'interface épurée de ChatLab.
Résumé
Dans cet article, nous avons parcouru l'architecture du système RAG dans la fonctionnalité des chatbots—de l'entrée des données à la génération de réponses. RAG est un composant fondamental des systèmes conversationnels modernes, permettant une utilisation efficace des connaissances externes. Des entreprises comme ChatLab intègrent activement cette technologie révolutionnaire dans leurs produits, offrant des capacités d'interaction avancées et intelligentes à leurs clients.
Bien que le système RAG présente une certaine complexité technique, son impact sur le texte généré par l'IA est indéniable. Le fait qu'il soit utilisé avec succès par des entreprises technologiques de premier plan comme Google, Microsoft et Amazon souligne son rôle crucial dans l'évolution dynamique de l'intelligence artificielle.
Prêt à découvrir la technologie RAG par vous-même ? Explorez les fonctionnalités de ChatLab ou apprenez comment créer votre propre chatbot IA alimenté par cette technologie.